MobileDiffusion:移动设备上的快速文本到图像生成 [译]
文本到图像的 扩散模型 在根据文本提示生成高质量图像方面表现出卓越的能力。然而,领先的模型特征数以十亿计的参数,因此运行成本高昂,需要强大的台式机或服务器(例如 Stable Diffusion、DALL·E 和 Imagen)。虽然过去一年在 Android 上通过 MediaPipe 和 iOS 上通过 Core ML 进行了推理解决方案的最新进展,但在移动设备上实现快速(不到一秒)的文本到图像生成仍然遥不可及。
为此,我们在论文「MobileDiffusion:移动设备上不到一秒的文本到图像生成」中介绍了一种用于移动设备上快速文本到图像生成的新方法。MobileDiffusion 是一种专为移动设备设计的高效潜在扩散模型。我们还采用 DiffusionGAN 在推理过程中实现一步采样,它对预训练的扩散模型进行微调,同时利用 GAN 对去噪步骤进行建模。我们已经在 iOS 和 Android 高端设备上测试了 MobileDiffusion,它可以在半秒内生成 512x512 的高质量图像。它相对较小,只有 520M 参数,使其特别适合于移动部署。

背景
文本到图像扩散模型的相对低效源于两个主要挑战。首先,扩散模型的固有设计需要 迭代去噪 来生成图像,这需要对模型进行多次评估。其次,文本到图像扩散模型中的网络架构复杂性涉及大量参数,通常达到数十亿,导致计算评估成本高昂。因此,尽管在移动设备上部署生成模型具有潜在的好处,例如增强用户体验和解决新出现的隐私问题,但在当前文献中它仍然相对未被探索。
在文本到图像扩散模型中推理效率的优化一直是一个活跃的研究领域。以前的研究主要集中在解决第一个挑战,寻求减少函数评估次数(NFEs)。利用先进的数值求解器(例如 DPM)或蒸馏技术(例如 渐进蒸馏、一致性蒸馏),必要的采样步骤数量已经从几百步
显著减少到个位数。一些最近的技术,如 DiffusionGAN 和 对抗性扩散蒸馏,甚至减少到只需一步。
然而,在移动设备上,即使是少量的评估步骤也可能因模型架构的复杂性而变慢。到目前为止,文本到图像扩散模型的架构效率相对较少受到关注。一些早期的工作简要地涉及了这个问题,包括移除冗余的神经网络块(例如 SnapFusion)。然而,这些努力缺乏对模型架构中每个组件的全面分析,因此未能提供设计高效架构的全面指南。
MobileDiffusion
有效克服移动设备有限计算能力带来的挑战,需要对模型架构效率进行深入和全面的探索。为了实现这一目标,我们的研究对 Stable Diffusion 的 UNet 架构 中的每个组成部分和计算操作进行了详细检查。我们提出了一份全面指南,用于打造高效的文本到图像扩散模型,最终形成了 MobileDiffusion。
MobileDiffusion 的设计遵循 潜在扩散模型。它包含三个组件:文本编码器、扩散 UNet 和图像解码器。对于文本编码器,我们使用 CLIP-ViT/L14,这是一个适用于移动设备的小型模型(125M 参数)。然后我们将重点转移到扩散 UNet 和图像解码器上。
扩散 UNet
如下图所示,扩散 UNet 通常交替使用变压器块和卷积块。我们对这两个基本构建块进行了全面的调查。在整个研究中,我们控制了训练流程(例如,数据、优化器)来研究不同架构的效果。
在经典的文本到图像扩散模型中,变压器块由一个自我关注层(SA)组成,用于建模视觉特征之间的长距离依赖,一个交叉关注层(CA)来捕捉文本条件和视觉特征之间的相互作用,以及一个前馈层(FF)来对注意力层的输出进行后处理。这些变压器块在文本到图像扩散模型中发挥着关键作用,是文本理解的主要组成部分。然而,它们也提出了一个重要的效率挑战,鉴于注意力操作的计算开销与序列长度呈二次方关系。我们遵循 UViT 架构的思路,在 UNet 的瓶颈处放置更多的变压器块。这一设计选择的动机是,在瓶颈处由于其较低的维度,注意力计算的资源消耗较少。
 |
| 我们的 UNet 架构在中间加入了更多的变压器,且在高分辨率下跳过了自我关注(SA)层。 |
特别是 ResNet 块的卷积块被部署在 UNet 的每个层级。虽然这些块对于特征提取和信息流动至关重要,但与之相关的计算成本,特别是在高分辨率层级,可能相当可观。在这方面,一个已经证明的方法是 可分离卷积。我们观察到,在 UNet 深层部分用轻量级可分离卷积层替换常规卷积层,可获得类似的性能。
在下图中,我们比较了几个扩散模型的 UNet。我们的 MobileDiffusion 在 FLOPs(浮点运算)和参数数量方面展现了卓越的效率。
 |
| 对几个扩散 UNet 的比较。 |
图像解码器
除了 UNet 外,我们还对图像解码器进行了优化。我们训练了一个 变分自动编码器(VAE),将 RGB 图像编码为一个 8 通道的潜在变量,其空间大小为图像的 8 倍较小。潜在变量可以解码为图像,并且大小增大 8 倍。为了进一步提高效率,我们设计了一个轻量级的解码器架构,通过修剪原始解码器的宽度和深度。最终的轻量级解码器导致显著的性能提升,几乎减少了 50% 的延迟,并提高了质量。更多细节,请参考我们的论文。
 |
| VAE 重构。我们的 VAE 解码器比 SD(Stable Diffusion)有更好的视觉质量。 |
| 解码器 | #参数 (M) | PSNR↑ | SSIM↑ | LPIPS↓ |
| SD | 49.5 | 26.7 | 0.76 | 0.037 |
| 我们的 | 39.3 | 30.0 | 0.83 | 0.032 |
| 我们的-轻量级 | 9.8 | 30.2 | 0.84 | 0.032 |
一步采样
除了优化模型架构外,我们还采用了 DiffusionGAN 混合 模
型实现一步采样。训练用于文本到图像生成的 DiffusionGAN 混合模型遇到了几个复杂性。特别是,鉴别器(一个区分真实数据和生成数据的分类器)必须基于纹理和语义做出判断。此外,训练文本到图像模型的成本可能极高,特别是在 GAN 基础模型的情况下,其中鉴别器引入了额外的参数。纯 GAN 基础的文本到图像模型(例如 StyleGAN-T、GigaGAN)面临类似的复杂性,导致训练过程高度复杂且成本高昂。
为了克服这些挑战,我们使用预训练的扩散 UNet 初始化生成器和鉴别器。这种设计使得可以无缝地使用预训练的扩散模型进行初始化。我们假设扩散模型内部的特征包含了文本和视觉数据复杂相互作用的丰富信息。这种初始化策略显著简化了训练过程。
下图展示了训练过程。初始化后,一个带噪声的图像被发送到生成器进行一步扩散。其结果通过重建损失进行评估,类似于扩散模型训练。然后我们向输出添加噪声,并将其发送到鉴别器,其结果通过 GAN 损失进行评估,有效地采用 GAN 对去噪步骤进行建模。通过使用预训练的权重初始化生成器和鉴别器,训练成为了一个微调过程,可以在不到 10K 次迭代中收敛。
 |
| DiffusionGAN 微调的示意图。 |
结果
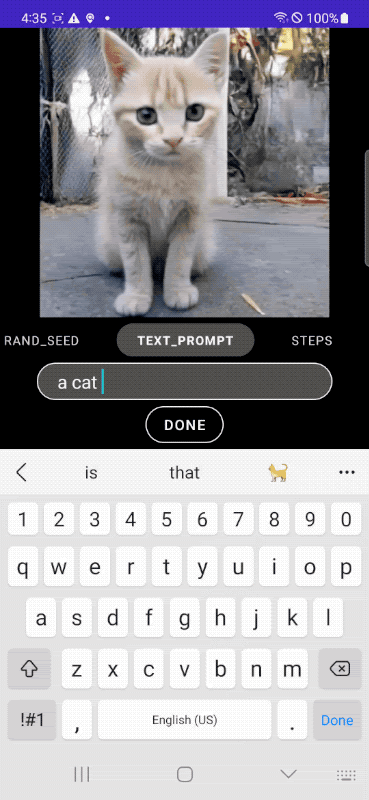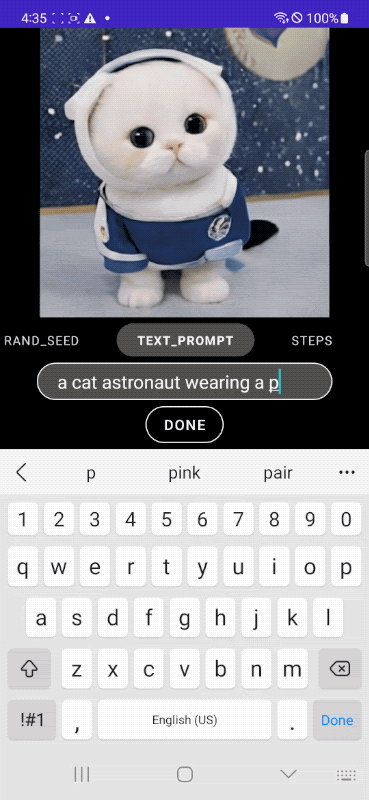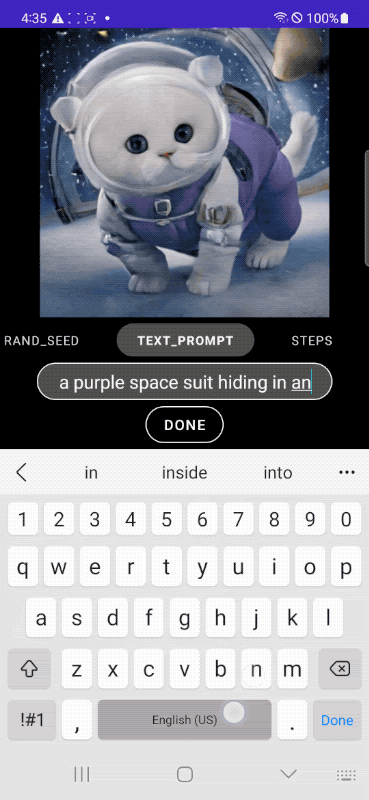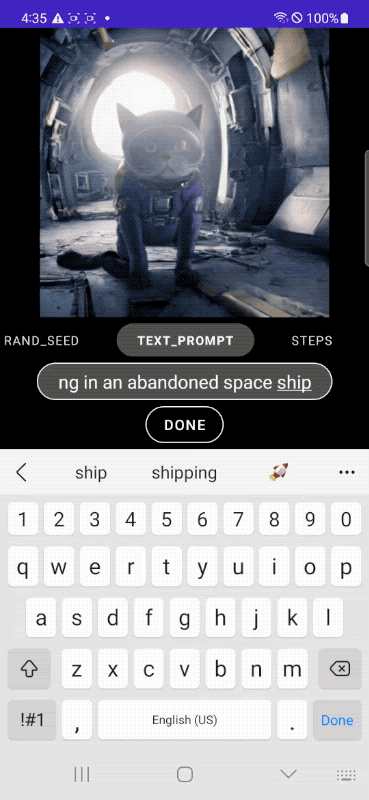
下面我们展示了使用我们的 MobileDiffusion 和 DiffusionGAN 一步采样生成的示例图像。借助如此紧凑的模型(总计 520M 参数),MobileDiffusion 可以为各种领域生成高质量多样化的图像。
 |
| 我们的 MobileDiffusion 生成的图像 |
我们在 iOS 和 Android 设备上测量了我们的 MobileDiffusion 的性能,使用了不同的运行时优化器。下面报告了延迟数据。我们看到 MobileDiffusion 非常高效,可以在半秒内生成 512x512 的图像。这种闪电般的速度可能使移动设备上的许多有趣用例成为可能。
 |
| 移动设备上的延迟测量(秒)。 |
结论
凭借在延迟和尺寸方面的卓越效率,MobileDiffusion 有潜力成为移动部署的非常友好的选择,因为它能够在输入文本提示时实现快速的图像生成体验。我们将确保此技术的任何应用都符合 Google 的负责任的 AI 实践。
致谢
我们要感谢协助我们将 MobileDiffusion 引入设备的合作者和贡献者:肖志胜、徐燕武、唐九强、贾浩林、卢茨·尤斯滕、丹尼尔·芬纳、罗纳德·沃茨劳、魏建宁、拉曼·萨罗金、李柱银、安德烈·库利克、张卓玲和马提亚斯·格伦德曼。
原文作者:Google Research Blog
原文链接:https://blog.research.google/2024/01/mobilediffusion-rapid-text-to-image.html