使用 Atlas Vector Search 进行语义搜索 [译]
引言
你是否曾经寻找某样东西,但却找不到合适的词汇来描述它?你是否记得一部电影的一些特点,但却记不得它的名字?你是否曾经想要找到一件和你以前拥有的运动衫一样的衣服,但却不知道如何搜索它?你是否在使用大型语言模型,但它们只知道直到 2021 年的信息?你是否想让它跟上时代的步伐?那么,向量搜索可能正是你所寻找的。
什么是向量搜索?
向量搜索是一项功能,允许你进行语义搜索,即基于意义进行数据搜索。这项技术采用机器学习模型,通常称为编码器,将文本、音频、图像或其他类型的数据转换为高维向量。这些向量捕捉了数据的语义意义,然后可以通过搜索找到基于向量在高维空间中“靠近”彼此的相似内容。这可以作为传统基于关键字的搜索技术的极好补充,但也因其增强大型语言模型(LLMs)能力的相关性而引发了极大的兴奋,通过提供 LLMs “知道”之外的基础事实。在搜索用例中,即使不知道确切的措辞,也可以找到相关结果。这项技术可以用于自然语言处理和推荐系统等各种情境。
注意:正如你可能已经知道的,MongoDB Atlas 自 2020 年以来一直支持全文搜索,允许你在 MongoDB 数据上进行丰富的文本搜索。向量搜索和文本搜索的核心区别在于,向量搜索是基于意义而不是明确的文本进行查询,因此也可以搜索超出纯文本之外的数据。
向量搜索的优点
-
语义理解:与搜索确切的匹配项不同,向量搜索允许进行语义搜索。这意味着即使查询词在索引中不存在,但短语的意义相似,它们仍然会被视为匹配项。
-
可扩展性:向量搜索可以在大型数据集上进行,使其非常适合在你拥有大量数据的用例中使用。
-
灵活性:包括文本在内的不同类型的数据,甚至非结构化数据,如音频和图像,都可以进行语义搜索。
基于 MongoDB 的向量搜索的优点
-
效率:通过将向量与原始数据一起存储,你可以避免在查询和写入时同步应用程序数据库和向量存储之间的数据。
-
一致性:将向量与数据一起存储可确保向量始终与正确的数据关联。在向量生成过程可能随时间改变的情况下,这可能很重要。通过存储向量,你可以确保始终拥有给定数据的正确向量。
-
简单性:将向量与数据一起存储简化了应用程序的整体架构。你不需要维护向量的单独服务或数据库,从而减少了系统中的复杂性和潜在故障点。
-
可扩展性:借助 MongoDB Atlas 的强大功能,MongoDB 上的向量搜索可以水平和垂直扩展,使你能够支持最苛刻的工作负载。
配置 MongoDB Atlas 集群
现在,让我们开始设置一个 MongoDB Atlas 集群,我们将使用它来存储我们的嵌入。
步骤 1:创建账户
要创建一个 MongoDB Atlas 集群,首先你需要创建一个 MongoDB Atlas 账户(如果你还没有的话)。访问 MongoDB Atlas 网站,然后点击「注册」。
步骤 2:构建新集群
创建账户后,你将被引导至 MongoDB Atlas 仪表板。你可以在仪表板中创建集群,或使用我们的公共 API、CLI 或 Terraform 提供程序。要在仪表板中执行此操作,请点击「创建集群」,然后选择共享集群选项。我们建议创建一个 M0 级别的集群。
如果你需要帮助,请查看我们的教程,演示了使用各种策略部署 Atlas 的过程。
步骤 3:创建你的集合
现在,我们将在集群中创建你的集合,以便我们可以插入数据。现在需要创建它们,以便你可以创建一个 Atlas trigger,用于定位它们。
对于本教程,如果你有要使用的数据,可以创建自己的集合。如果你想使用我们的样本数据,你需要首先在集群中创建一个空集合,以便我们可以设置 trigger 来嵌入它们。现在就使用 UI 创建一个「sample_mflix」数据库和「movies」集合吧,如果你想使用我们的样本数据。
设置 Atlas trigger
我们将创建一个 Atlas trigger,每当集群中插入新文档时调用 OpenAI API。
要使用 OpenAI 进行下一步操作,你需要在 OpenAI 上设置一个账户并创建一个 API 密钥:
步骤 1:创建 trigger
要创建 trigger,请导航至 MongoDB Atlas 仪表板中的「Triggers」部分,然后点击「添加 Trigger」。

步骤 2:为你的 OpenAI 凭证设置秘密和值
转到「App Services」并选择你的「Triggers」应用。

点击「Values」。

你将需要自己的 OpenAI API 密钥,你可以在他们的网站上创建。

创建一个新 Value

选择 Secret,然后把 OpenAI API key 粘贴进去。
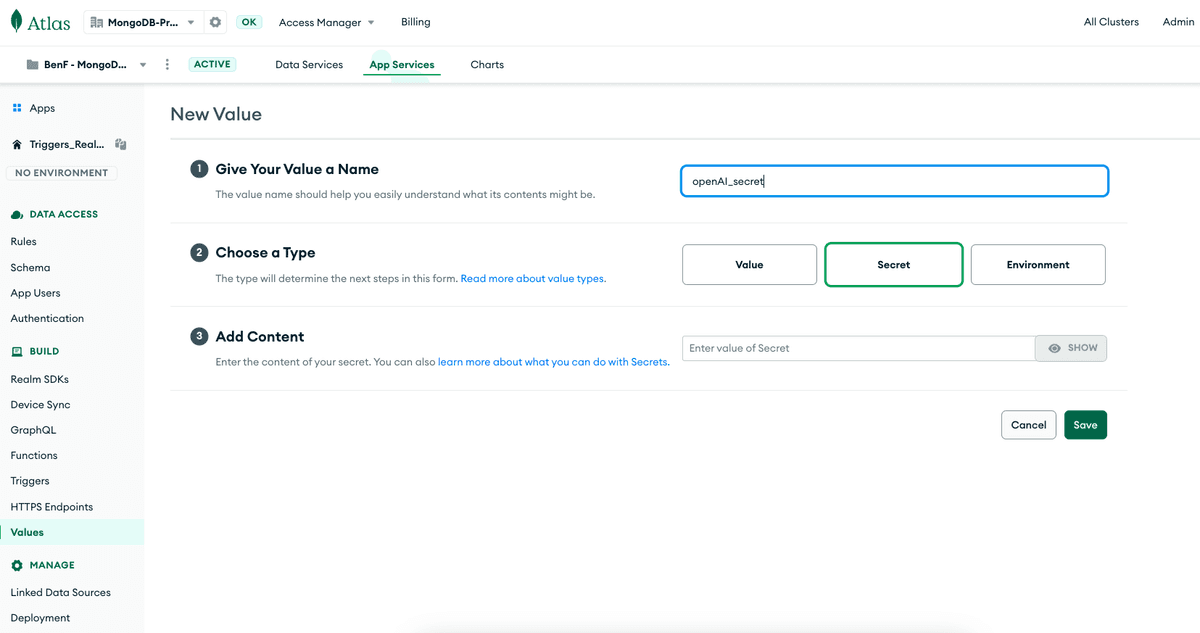
然后,创建另一个值(选择 Type 为 Value),并将其链接到您的 Secret。这样就可以在你的 trigger 中安全地引用 API key 了。

现在,你可以返回到「Data Services」选项卡并进入 triggers 菜单。如果你之前创建的 trigger 没有显示,只需添加一个新的 trigger。它将能够使用你之前在 App Services 中设置的值。
步骤 3:配置 trigger
为你的 trigger 选择「数据库」类型。然后,链接源集群,并将「Trigger Source Details」设置为监视更改的数据库和集合。对于本教程,我们使用的是「sample_mflix」数据库和「movies」集合。将操作类型设置为 Insert、Update、Replace 操作。选中「Full Document」标志,在事件类型中选择「Function」。
在 Function Editor 中,使用下面的代码片段,将数据库名称和集合名称替换为你想要使用的名称。
此 trigger 将看到此集合中何时创建或更新了新文档。一旦发生这种情况,它将调用 OpenAI API 来创建所需字段的嵌入,然后将该向量嵌入插入到具有新字段名称的文档中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
exports = async function(changeEvent) {
// 获取 changeEvent 中的完整文档。
const doc = changeEvent.fullDocument;
// 定义 OpenAI API 的 URL 和密钥。
const url = 'https://api.openai.com/v1/embeddings';
// 使用 App Services 中 "Values" 工具内给你的 API 密钥设定的名称
const openai_key = context.values.get("openAI_value");
try {
// 打印出正在处理的文档的 id
console.log(`正在处理 id 为:${doc._id} 的文档`);
// 调用 OpenAI API 获取 embeddings
let response = await context.http.post({
url: url,
headers: {
'Authorization': [`Bearer ${openai_key}`],
'Content-Type': ['application/json']
},
body: JSON.stringify({
// 你的文档内包含要嵌入的数据的字段,在这里是样例电影数据中的 "plot" 字段。
input: doc.plot,
model: "text-embedding-ada-002"
})
});
// 解析 JSON 响应
let responseData = EJSON.parse(response.body.text());
// 检查响应状态码。
if(response.statusCode === 200) {
console.log("成功获取 embedding。");
const embedding = responseData.data[0].embedding;
// 使用你的 MongoDB Atlas 集群的名称
const collection = context.services.get("<CLUSTER_NAME>").db("sample_mflix").collection("movies");
// 在 MongoDB 中更新文档。
const result = await collection.updateOne(
{ _id: doc._id },
// 你想要包含 embeddings 的新字段的名称。
{ $set: { plot_embedding: embedding }}
);
if(result.modifiedCount === 1) {
console.log("成功更新了文档。");
} else {
console.log("更新文档失败。");
}
} else {
console.log(`获取 embedding 失败。状态码:${response.statusCode}`);
}
} catch(err) {
// 打印出任何错误
console.error(err);
}
};
配置索引
现在,转到 Atlas Search 并创建一个索引。使用 JSON 索引定义并插入以下内容,将嵌入字段名称替换为你选择的字段。如果你使用的是 sample_mflix 数据库,它应该是「plot_embedding」,并给它一个名字。我在使用样本数据的设置中使用了「moviesPlotIndex」。
首先,点击集群上的「搜索」选项卡
然后,点击「创建搜索索引」。

创建「JSON 编辑器」。

然后,在左侧选择你的数据库和集合,并在下面的代码片段中插入你的索引定义。

1
2
3
4
5
6
7
8
9
10
11
12
{
"mappings": {
"dynamic": true,
"fields": {
"plot_embedding": {
"dimensions": 1536,
"similarity": "cosine",
"type": "knnVector"
}
}
}
}
插入你的数据
现在,你需要插入你的数据。随着你的数据被插入,它将使用脚本进行嵌入,然后使用我们刚刚设置的 KNN 索引进行索引。
如果你有自己的数据,你现在可以使用 MongoImports 等工具插入。
如果你要使用样本电影数据,你可以转到集群,点击 … 菜单,并加载样本数据。如果一切设置正确,sample_mflix 数据库和 movies 集合将在「plot」字段上创建 plot 嵌入,并添加到新的「plot_embeddings」字段中。
使用 JavaScript 查询你的数据
一旦你的集合中的文档生成了嵌入,你就可以执行查询。但是由于这是使用向量搜索,所以你的查询需要转换为嵌入。这是一个示例脚本,说明了如何添加一个函数来获取查询的嵌入,以及如何在应用程序中使用该嵌入的函数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
const axios = require('axios'); // 引入 axios 库,用于 HTTP 请求
const MongoClient = require('mongodb').MongoClient; // 引入 MongoDB 的客户端库
// 异步函数,用于获取文本嵌入(embedding)
async function getEmbedding(query) {
// 定义 OpenAI API 的 URL 和密钥
const url = 'https://api.openai.com/v1/embeddings';
const openai_key = 'your_openai_key'; // 请替换为你自己的 OpenAI 密钥
// 调用 OpenAI API 来获取文本嵌入
let response = await axios.post(url, {
input: query,
model: "text-embedding-ada-002"
}, {
headers: {
'Authorization': `Bearer ${openai_key}`,
'Content-Type': 'application/json'
}
});
// 检查响应状态
if(response.status === 200) {
return response.data.data[0].embedding;
} else {
throw new Error(`Failed to get embedding. Status code: ${response.status}`);
}
}
// 异步函数,用于在 MongoDB 中查找与给定嵌入相似的文档
async function findSimilarDocuments(embedding) {
const url = 'your_mongodb_url'; // 请替换为你自己的 MongoDB URL
const client = new MongoClient(url);
try {
await client.connect(); // 连接到 MongoDB
const db = client.db('<DB_NAME>'); // 请替换为你的数据库名
const collection = db.collection('<COLLECTION_NAME>'); // 请替换为你的集合名
// 使用聚合查询来找到相似的文档
const documents = await collection.aggregate([
{"$vectorSearch": {
"queryVector": embedding,
"path": "plot_embedding",
"numCandidates": 100,
"limit": 5,
"index": "moviesPlotIndex",
}}
]);
return documents;
} finally {
await client.close(); // 关闭 MongoDB 连接
}
}
// 主函数
async function main() {
const query = 'your_query'; // 请替换为你的查询文本
try {
const embedding = await getEmbedding(query); // 获取查询文本的嵌入
const documents = await findSimilarDocuments(embedding); // 查找相似的文档
console.log(documents); // 打印找到的文档
} catch(err) {
console.error(err); // 打印任何错误
}
}
main(); // 运行主函数
此脚本首先使用 OpenAI API 将你的查询转换为嵌入,然后查询你的 MongoDB 集群中具有类似嵌入的文档。
请记得用你实际的 OpenAI 密钥、MongoDB URL、查询、数据库名称和集合名称分别替换 ‘your_openai_key’、’your_mongodb_url’、’your_query’、’test’ 和 ‘embeddings’。
就是这样!你已成功设置了一个 MongoDB Atlas 集群和 Atlas trigger,当文档插入集群时调用 OpenAI API 进行嵌入,并执行了向量搜索查询。
原文作者:Benjamin Flast
原文链接:https://www.mongodb.com/developer/products/atlas/semantic-search-mongodb-atlas-vector-search